




PostgreSQL���g���v�� - ��31�v��SQL�{������
���WӍ������OCP�J�C���ڈ����У���ԇ�ˆT�^��Ո�M������@ȡ�����ԇ�r�g�������M��Ոϵ�ھ��ώ������Ĺٷ��J�C���������٣�
��Ҫ��ԃ
PostgreSQL��С�����ң��Ǐ����T��u����������һ��ϵ�н̳̣����ݰ�����PG���A���J֪���������bʹ�á�������ɫ���ޡ������S�o���������ȃ��ݣ�ϣ�������PG���W��PG��ͬ�W���Ў������gӭ���m�PעCUUG PG���g���v�á�
��31�v��SQL�{������
��31�v��10��28��(����)19:30-20:30�������ęn��ҕ�l��ϵCUUG
����1 : SQL�{����ʽ
����2 : �����ԃ�{������
����3 : �����ԃ���ð���
�_�l��ʽһ
�� ��Ҫ�p�װ��ֶ�Ƕ�뵽���_ʽ
��sal���������������Ǘl���Z���а�sal�з����˱��_ʽ���У��������������֣�����������惦�����sal�е�ֵ��������sal����100�Ժ��ֵ��
testdb=# explain select * from emp2 where sal + 100 = 2000;
QUERY PLAN
-------------------------------------------------------------------------
Gather (cost=1000.00..7796.60 rows=2294 width=36)
Workers Planned: 2
-> Parallel Seq Scan on emp2 (cost=0.00..6567.20 rows=956 width=36)
Filter: ((sal + 100) = 2000)
(4 rows)
�� ����
ͨ�^��ʽ�ȓQ����sal�Џı��_ʽ�Є��x�������͕��õ�������
testdb=# explain select * from emp2 where sal = 2000 - 100;
QUERY PLAN
--------------------------------------------------------------------------
Index Scan using emp2_sal_ind on emp2 (cost=0.42..8.44 rows=1 width=36)
Index Cond: (sal = 1900)
(2 rows)
�_�l��ʽ��
�� ��Ҫ�p�װ��ֶ�Ƕ�뵽������
��hiredate���������������Ǘl���Z���а�ԓ�з����˺������У��������������֣�����������惦�����ԓ�е�ֵ�������Ǻ���̎���Ժ��ֵ��
testdb=# explain select * from emp2 where to_char(hiredate,'dd-mm-yyyy')='22-05-2022';
QUERY PLAN
----------------------------------------------------------------------------------------------------
Seq Scan on emp2 (cost=0.00..289.32 rows=50 width=62)
Filter: (to_char((hiredate)::timestamp with time zone, 'dd-mm-yyyy'::text) = '22-05-2022'::text)
�� ����
ͨ�^��ʽ�D�Q�����Џĺ����Є��x�������͕��õ����������^�ɱ�����e�ܴ�
testdb=# explain select * from emp2 where hiredate=to_date('22-05-2022','dd-mm-yyyy');
QUERY PLAN
----------------------------------------------------------------------------
Index Scan using emp2_hiredate on emp2 (cost=0.29..8.30 rows=1 width=62)
Index Cond: (hiredate = to_date('22-05-2022'::text, 'dd-mm-yyyy'::text))
�_�l��ʽ��
�� �����ԃ�б��^�̶���ԃijЩ�У����Ի����@�ׂ��н��ͺ�������ֱ�Ӳ�ԃ���������_�ر���衣
create index emp2_empno on emp2 (empno,sal);
testdb=# explain select empno,sal from emp2 where empno=7788;
QUERY PLAN
-----------------------------------------------------------------------------
Index Only Scan using emp2_empno on emp2 (cost=0.29..10.09 rows=2 width=8)
Index Cond: (empno = 7788)
�����ԃָ�����
�� OLTP����SQL�{��ָ�����
-- �ӱ����кܺõėl�����ƣ�ͬ�r���ӱ��ϵ������ԗl���ֶ��ϑ�ԓ���������������I��Ψһ�����������������ͺ������ȡ�
-- ��ÿ���B�Ӳ���֮��M�����C����ӛ䛔����٣����f�o��һ���B�Ӳ�����
-- �������ص��еĔ����������_���B�ӷ�ʽ��
-- �M��ͨ�^�ڱ��ӱ����B���ֶ��ϵ��������L�����ӱ���
-- �α���葪ԓ��Ч�ʣ�������ӱ���߀���������Ɨl����������ѭ�ͺ���������ԭ�t���������m�ďͺ�����(�B���ֶ��c�l���ֶ�)��
-- ȫ�����Ҳ�S�Ǻ����ģ���������С�������a�����L����
-- ������ƣ����������б����B�Ӳ�����
�� ����B���{�����w˼·
>> �����OLTP���ã��t������˼·����С�������������������ӛ����ٵ��B���_ʼ������������������B�ӣ������L��ÿ����r������ʹ���������e�Ǐͺ��������g��
>> �����OLAP���ã��t����˼·������hash�B�ӼӲ���̎�������B�����������Ҫ�ġ�
�� ����B�Ӄ�������һ
testdb=# explain select e.*,d.*
from emp e,dept d
where d.deptno=e.deptno
and e.empno=7499;
QUERY PLAN
-----------------------------------------------------------------------------
Nested Loop (cost=0.30..16.36 rows=1 width=192)
-> Index Scan using pk_emp on emp e (cost=0.15..8.17 rows=1 width=98)
Index Cond: (empno = 7499)
-> Index Scan using pk_dept on dept d (cost=0.15..8.17 rows=1 width=94)
Index Cond: (deptno = e.deptno)
����Ӌ�����x��
1���Ȱ��ս�����empno�ֶ��ϵ�����ȥemp����ԃempno��7499�ĆT����Ϣ��
2���ٸ���7499���ڵIJ��T̖(deptno)ȥdept����ԃԓ���T��Ԕ����Ϣ������dept����deptno�ֶ��ϑ�ԓ��������
3�����ʹ��Ƕ��ѭ�h�B�ӷ�ʽ̎�픵����
���h��
������Ƕ���B��sql�Z�䣬ע���ӱ����B���ֶ��Ƿ���Ҫ������������
�������У����ӱ���dept��dept�����B���ֶ���deptno����emp��deptno�ֶ��ǿ��Բ���Ҫ�������ģ�����ѽ������l���ֶ������L���ӱ���
�� ����B�Ӄ���������
testdb=# explain select e.*,d.*
from emp e,dept d
where d.deptno=e.deptno
and e.empno=7499
and d.dname='DALLAS';
QUERY PLAN
-----------------------------------------------------------------------------
Nested Loop (cost=0.30..20.35 rows=1 width=192)
-> Index Scan using pk_emp on emp e (cost=0.15..8.17 rows=1 width=98)
Index Cond: (empno = 7499)
-> Index Scan using pk_dept on dept d (cost=0.15..8.17 rows=1 width=94)
Index Cond: (deptno = e.deptno)
Filter: ((dname)::text = 'DALLAS'::text)
����Ӌ�����x��
1���Ȱ��ս�����empno�ֶ��ϵ�����ȥemp����ԃempno��7499�ĆT����Ϣ��
2���ٸ���7499���ڵIJ��T̖(deptno)ȥdept����ԃԓ���T��Ԕ����Ϣ���˕rdept��߀��һ���l���ֶ�loc=��DALLAS������˿ɿ��]��(deptno,loc)�ͺ�������ʽȥ��ԃdept����Ч�ʸ��ߣ����ɽ���(deptno,loc)�ֶ��ϵďͺ�����(idx_dept_2)��
3�������Ƕ��ѭ�h���B�ӷ�ʽ̎�픵����
���h��
������Ƕ���B��sql�Z�䣬ע���Ƿ�����ڱ��ӱ����B���ֶ��cԓ���������s���l���ֶ��τ����ͺ�������������������dept���τ���(deptno�cdname)�ֶεďͺ�������
����Ӌ�����x(�m)
��ԓ��ѭ�P�ڏͺ����������r�Ľ��h��
��������ֶ������I����Ψһ�ֶΣ����߿��x�Էdz��ߵ��ֶΣ��M�ܼs���l���ֶα��^�̶���Ҳ��һ��Ҫ���ɏͺ��������ɽ��Ɇ��ֶ����������͏ͺ������_�N����
*����ͨ�^���^�l�F�@�N��r�������������Ȅ����ͺ�������ԃ�ĕr����rҪ�͵Ķࡣ�����ڱ����У�����ԓ�����ͺ�������
�����ԃ���ð���
�� 5����ԃ���ð���
SELECT emp.last_name,emp.first_name,j.job_title,d.department_name,l.city,l.state_province,l.postal_code,l.street_address,emp.email,emp.phone_number,emp.hire_date,emp.salary,mgr.last_name
from hr.employees emp,hr.employees mgr,hr.departments d,hr.locations l,hr.jobs j
where l.city='South San Francisco'
and emp.manager_id=mgr.employee_id
and emp.department_id=d.department_id
and d.location_id=l.location_id
and emp.job_id=j.job_id;
�� ��һ�N��r���o����
�ڛ]���κ���������r�²鿴�����Ӌ�� �����ڛ]���������������В��跽ʽ����ȫ����裬�B�ӷ�ʽ��hash join��
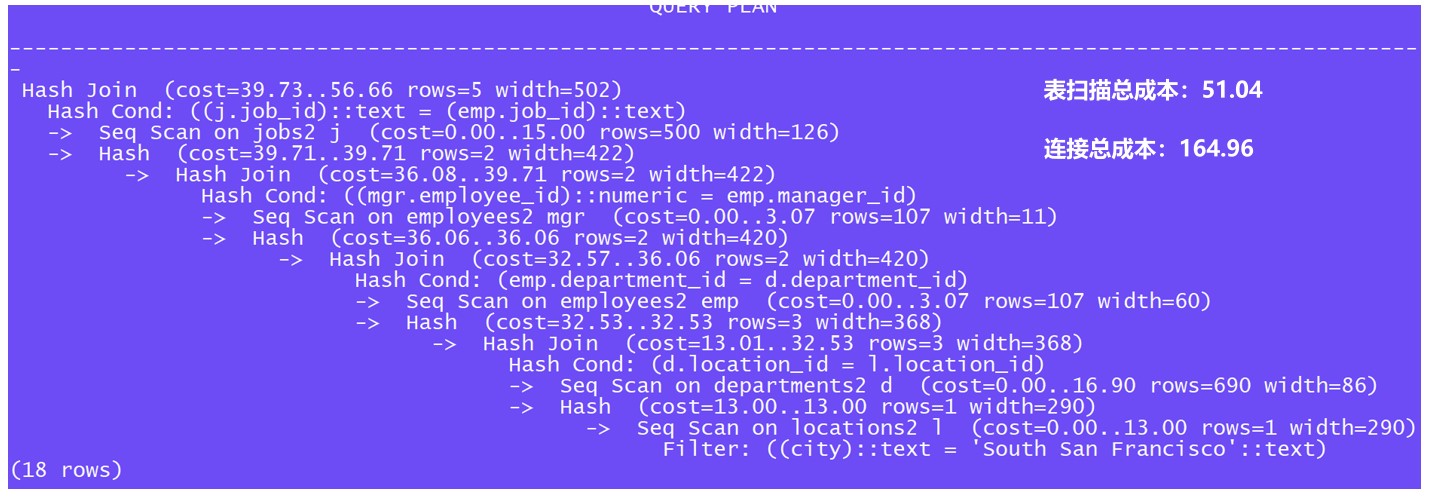
�� �ڶ��N��r��������������
��locations��city��location_id����������
��departments��location_id������
��departments��department_id�����I�s��
��employees��employee_id�����I�s��
��jobs��job_id�����I�s����

�� �����N��r�������ͺ�����
��locations��city��location_id���τ����ͺ�������
��departments��department_id ��location_id�τ����ͺ�����
��employees��employee_id�� department_id��manager_id��job_id�τ����ͺ�����(���߆�������)
��jobs��job_id�����I�s����

�� ���N����Ӌ���ɱ�����

���^�����l�F������B�ӷ�ʽ�܉���Ƕ��ѭ�h����ô��ɱ��������B�ӷ�ʽ���ͣ���Ȼ�҂�Ҫ�ṩ�l���������Ԅ��x��ɱ���͵��B�ӷ�ʽ��ֻҪ��һ�������L����ʽ���������裬��ô�B�ӷ�ʽһ����x��Ƕ��ѭ�h��
Employees���ďͺ������ڈ���Ӌ�����������ã������x�����B�ӗl������( employee_id,department_id,manager_id )��������������
Departments��locations����ӛ䛱��^�٣���ʹ�����ˆ��л��߶���������������ʹ��������
�B�������L->D->EMP-MGR-J

PostgreSQL���T����ͨ 100+ ���W���Y��

- Ƚ�˾V-�ώ�CUUG�����v��
- Ƚ�ώ� CUUG�����v�� Oracle��RedHat���v����Unix/Linux �Y���...[Ԕ���˽��ώ�]

- ��l��-�ώ�CUUG�����v��
- ��ώ� CUUG�����v�� ��ͨOracle��������ݻ֏͡����܃��� 11��Ora...[Ԕ���˽��ώ�]






